Head-to-head evaluations are useful for evaluating your LLM outputs against one another to
determine which models are generally better at a given task. However, they do not provide precise
metrics on how often a given model makes a certain error, only how often it outperforms another
model. For more precise metrics, please consider criteria or
code evaluations.
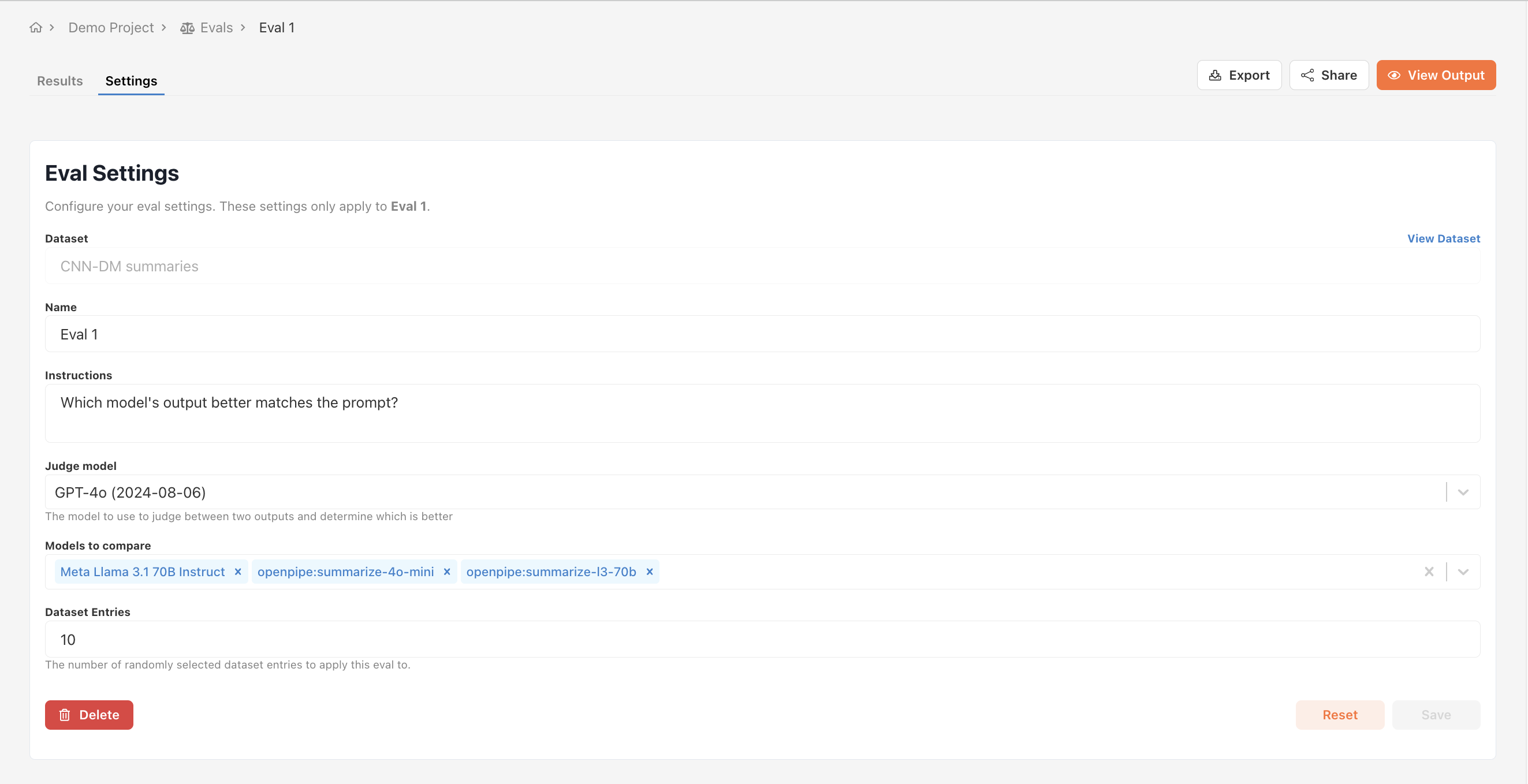
The number of comparisons performed in a head to head eval scales linearly with the number of
entries and quadratically with the number of models. If you’re evaluating 2 models on 100 entries,
there will be 100 * 1 = 100 comparisons. If you’re evaluating 3 models on 100 entries, there will
be 100 * 2 + 100 * 1 = 300 comparisons.

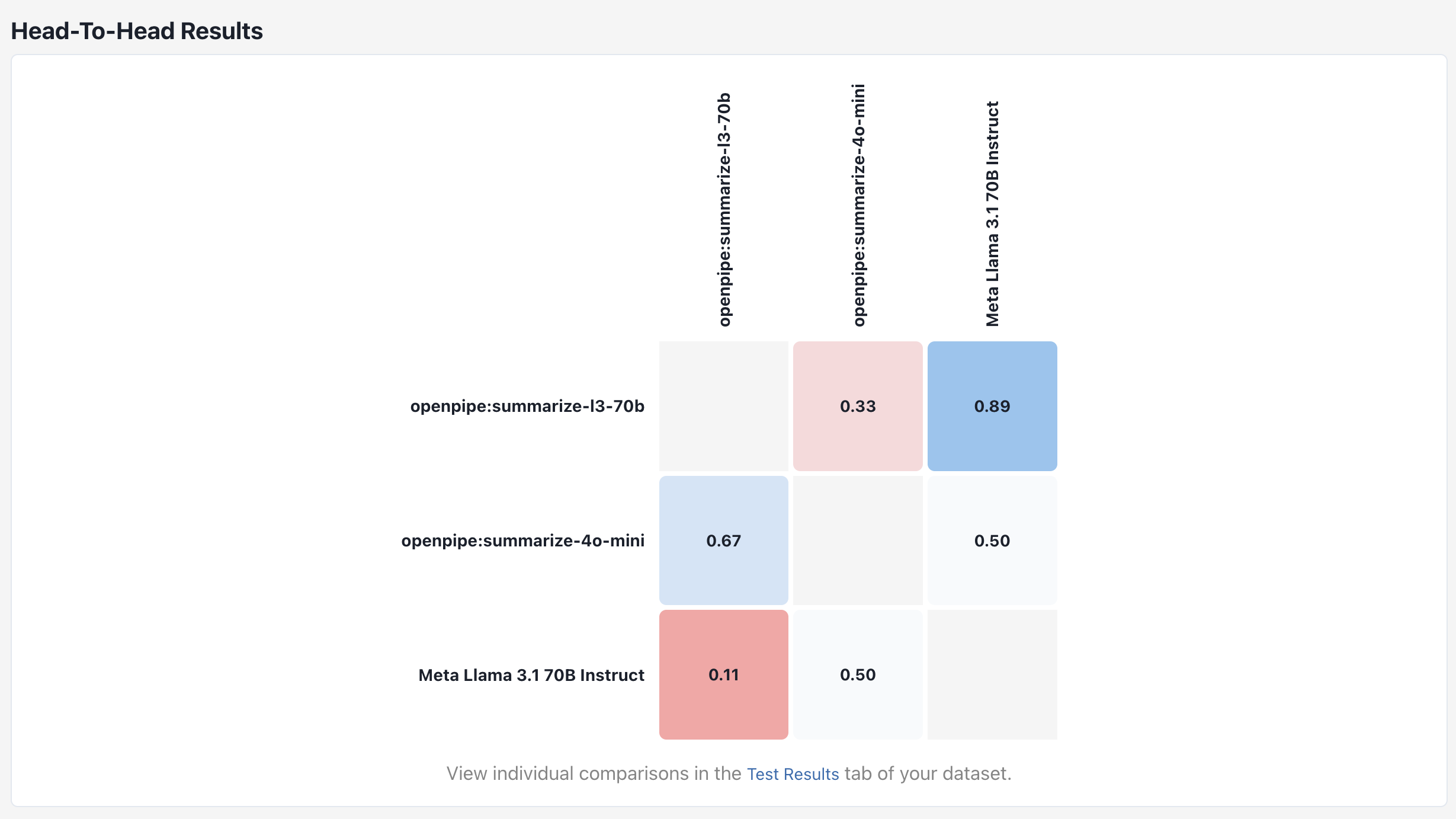
In addition to the results table, you can also view results in a matrix format. This is useful for visualizing how specific models perform against one another.
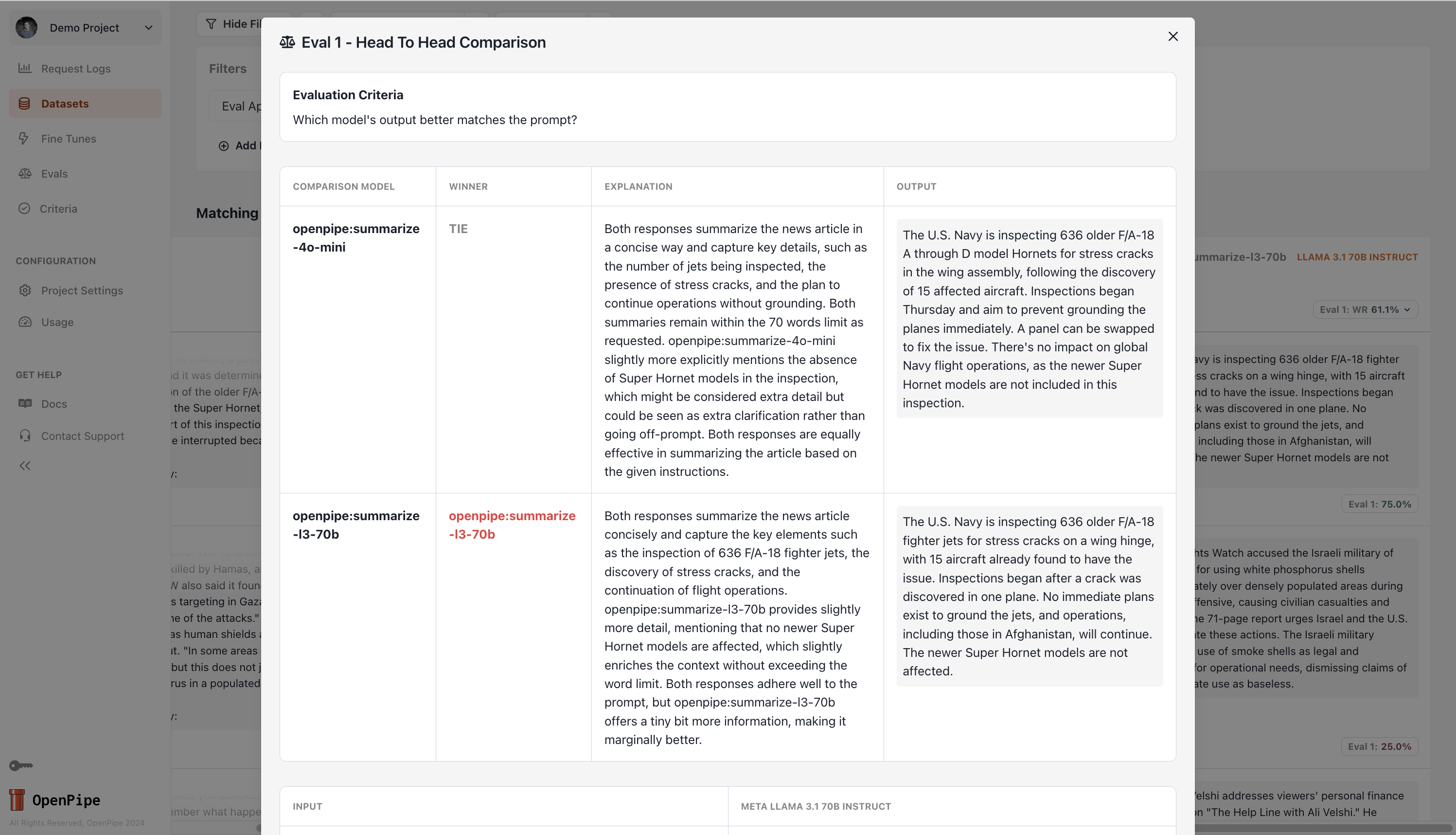
To see why one model might be outperforming another, you can navigate back to the evaluation table and click on a result pill to see the evaluation judge’s reasoning.
While head-to-head evaluations are convenient, they can quickly become expensive to run, and provide limited insight into how well a model performs. For more precise metrics, consider criterion or code evaluations.